225
0
685
高级会员
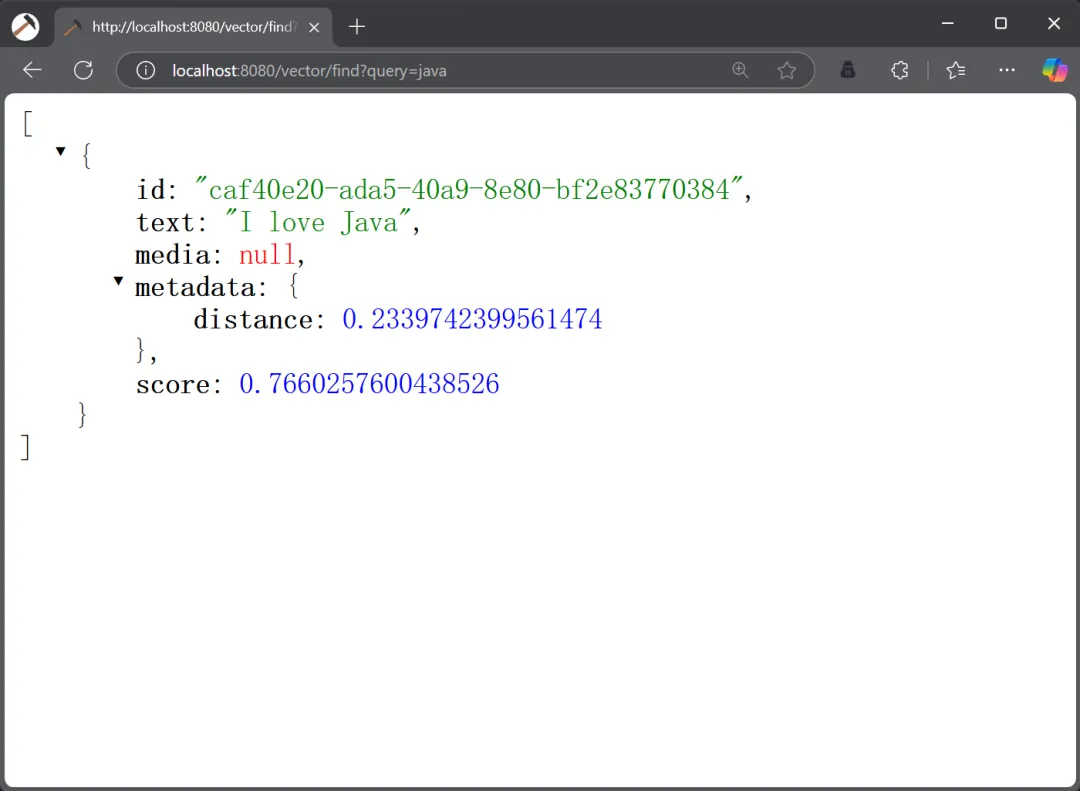
“PS:准确来说 Vector Database 和 Vector Store 不完全相同,前者主要用于“向量”数据的存储,而 Vector Store 是用于存储和检索向量数据的组件。
“想要获取完整案例的同学加V:vipStone【备注:向量】
举报
本版积分规则 发表回复 回帖后跳转到最后一页
|智能设备 | 粤ICP备2024353841号-1
GMT+8, 2025-4-3 16:05 , Processed in 0.961978 second(s), 29 queries .
Powered by 智能设备
©2025